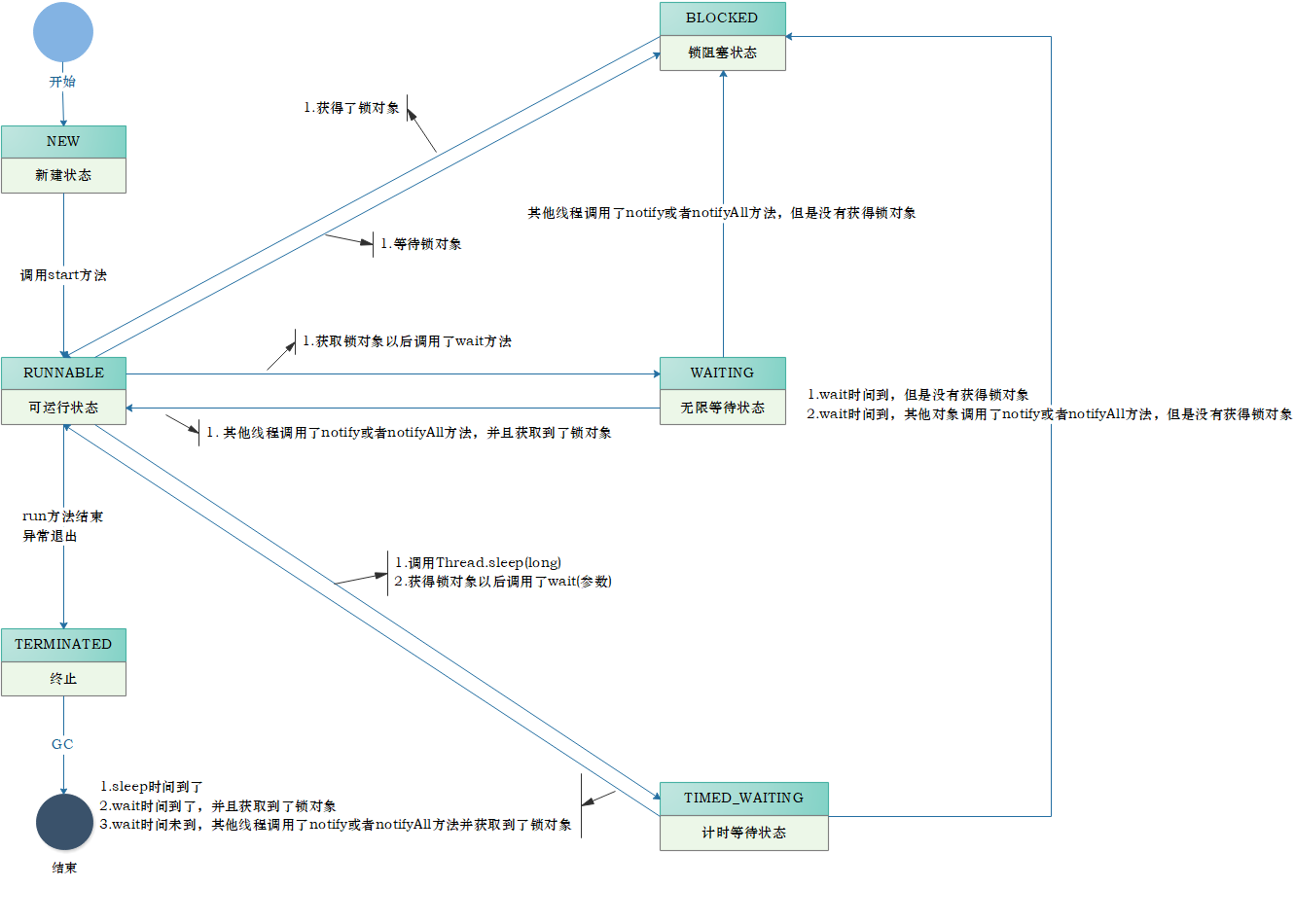
1 线程状态 1.1 状态介绍 当线程被创建并启动以后,它既不是一启动就进入了执行状态,也不是一直处于执行状态。线程对象在不同的时期有不同的状态。那么Java中的线程存在哪几种状态呢?Java中的线程
状态被定义在了java.lang.Thread.State枚举类中,State枚举类的源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public class Thread { public enum State { NEW , RUNNABLE , BLOCKED , WAITING , TIMED_WAITING , TERMINATED; } public State getState () { return jdk.internal.misc.VM.toThreadState(threadStatus); } }
通过源码我们可以看到Java中的线程存在6种状态,每种线程状态的含义如下
线程状态
具体含义
NEW
一个尚未启动的线程的状态。也称之为初始状态、开始状态。线程刚被创建,但是并未启动。还没调用start方法。MyThread t = new MyThread()只有线程象,没有线程特征。
RUNNABLE
当我们调用线程对象的start方法,那么此时线程对象进入了RUNNABLE状态。那么此时才是真正的在JVM进程中创建了一个线程,线程一经启动并不是立即得到执行,线程的运行与否要听令与CPU的调度,那么我们把这个中间状态称之为可执行状态(RUNNABLE)也就是说它具备执行的资格,但是并没有真正的执行起来而是在等待CPU的度。
BLOCKED
当一个线程试图获取一个对象锁,而该对象锁被其他的线程持有,则该线程进入Blocked状态;当该线程持有锁时,该线程将变成Runnable状态。
WAITING
一个正在等待的线程的状态。也称之为等待状态。造成线程等待的原因有两种,分别是调用Object.wait()、join()方法。处于等待状态的线程,正在等待其他线程去执行一个特定的操作。例如:因为wait()而等待的线程正在等待另一个线程去调用notify()或notifyAll();一个因为join()而等待的线程正在等待另一个线程结束。
TIMED_WAITING
一个在限定时间内等待的线程的状态。也称之为限时等待状态。造成线程限时等待状态的原因有三种,分别是:Thread.sleep(long),Object.wait(long)、join(long)。
TERMINATED
一个完全运行完成的线程的状态。也称之为终止状态、结束状态
各个状态的转换,如下图所示:
1.2 案例演示 为了验证上面论述的状态即状态转换的正确性,也为了加深对线程状态转换的理解,下面通过三个案例演示线程间中的状态转换。
1.2.1 案例一 本案例主要演示TIME_WAITING的状态转换。
需求:编写一段代码,依次显示一个线程的这些状态:NEW -> RUNNABLE -> TIME_WAITING -> RUNNABLE -> TERMINATED
为了简化我们的开发,本次我们使用匿名内部类结合lambda表达式的方式使用多线程。
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class ThreadStateDemo01 { public static void main (String[] args) throws InterruptedException { Thread thread = new Thread (() -> { System.out.println("2.执行thread.start()之后,线程的状态:" + Thread.currentThread().getState()); try { Thread.sleep(100 ); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("4.执行Thread.sleep(long)完成之后,线程的状态:" + Thread.currentThread().getState()); }); System.out.println("1.通过new初始化一个线程,但是还没有start()之前,线程的状态:" + thread.getState()); thread.start(); Thread.sleep(50 ); System.out.println("3.执行Thread.sleep(long)时,线程的状态:" + thread.getState()); Thread.sleep(100 ); System.out.println("5.线程执行完毕之后,线程的状态:" + thread.getState() + "\n" ); } }
控制台输出
1 2 3 4 5 1. 通过new 初始化一个线程,但是还没有start()之前,线程的状态:NEW2. 执行thread.start()之后,线程的状态:RUNNABLE3. 执行Thread.sleep(long )时,线程的状态:TIMED_WAITING4. 执行Thread.sleep(long )完成之后,线程的状态:RUNNABLE5. 线程执行完毕之后,线程的状态:TERMINATED
1.2.2 案例二 本案例主要演示WAITING的状态转换。
需求:编写一段代码,依次显示一个线程的这些状态:NEW -> RUNNABLE -> WAITING -> RUNNABLE -> TERMINATED
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 public class ThreadStateDemo02 { public static void main (String[] args) throws InterruptedException { Object obj = new Object (); Thread thread1 = new Thread (() -> { System.out.println("2.执行thread.start()之后,线程的状态:" + Thread.currentThread().getState()); synchronized (obj) { try { Thread.sleep(100 ); obj.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.println("4.被object.notify()方法唤醒之后,线程的状态:" + Thread.currentThread().getState()); }); System.out.println("1.通过new初始化一个线程,但是还没有start()之前,线程的状态:" + thread1.getState()); thread1.start(); Thread.sleep(150 ); System.out.println("3.执行object.wait()时,线程的状态:" + thread1.getState()); new Thread (() -> { synchronized (obj) { obj.notify(); } }).start(); Thread.sleep(10 ); System.out.println("5.线程执行完毕之后,线程的状态:" + thread1.getState() + "\n" ); } }
控制台输出结果
1 2 3 4 5 1. 通过new 初始化一个线程,但是还没有start()之前,线程的状态:NEW2. 执行thread.start()之后,线程的状态:RUNNABLE3. 执行object.wait()时,线程的状态:WAITING4. 被object.notify()方法唤醒之后,线程的状态:RUNNABLE5. 线程执行完毕之后,线程的状态:TERMINATED
1.2.3 案例三 本案例主要演示BLOCKED的状态转换。
需求:编写一段代码,依次显示一个线程的这些状态:NEW -> RUNNABLE -> BLOCKED -> RUNNABLE -> TERMINATED
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 public class ThreadStateDemo03 { public static void main (String[] args) throws InterruptedException { Object obj2 = new Object (); new Thread (() -> { synchronized (obj2) { try { Thread.sleep(100 ); obj2.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } }).start(); Thread thread = new Thread (() -> { System.out.println("2.执行thread.start()之后,线程的状态:" + Thread.currentThread().getState()); synchronized (obj2) { try { Thread.sleep(100 ); obj2.notify(); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.println("4.阻塞结束后,线程的状态:" + Thread.currentThread().getState()); }); System.out.println("1.通过new初始化一个线程,但是还没有thread.start()之前,线程的状态:" + thread.getState()); thread.start(); Thread.sleep(50 ); System.out.println("3.因为等待锁而阻塞时,线程的状态:" + thread.getState()); Thread.sleep(300 ); System.out.println("5.线程执行完毕之后,线程的状态:" + thread.getState()); } } Object obj = new Object (); Thread t1 = new Thread (()->{ synchronized (obj){ try { Thread.sleep(1000 ); } catch (InterruptedException e) { e.printStackTrace(); } } }); t1.start(); Thread t2 = new Thread (()->{ System.out.println("线程开启之后的状态" + Thread.currentThread().getState()); synchronized (obj){ System.out.println("进入之后的状态" + Thread.currentThread().getState()); } }); System.out.println("创建线程对象后,但是不调用start方法的状态" + t2.getState()); t2.start(); Thread.sleep(100 ); System.out.println(t2.getState()); Thread.sleep(2000 ); System.out.println(t2.getState());
控制台输出结果
1 2 3 4 5 1. 通过new 初始化一个线程,但是还没有thread.start()之前,线程的状态:NEW2. 执行thread.start()之后,线程的状态:RUNNABLE3. 因为等待锁而阻塞时,线程的状态:BLOCKED4. 阻塞结束后,线程的状态:RUNNABLE5. 线程执行完毕之后,线程的状态:TERMINATED
通过上面3个案例的代码演示,我们可以证明开始章节说所述的线程状态以及线程状态转换都是正确的。
2 线程池 2.1 概述 提到池,大家应该能想到的就是水池。水池就是一个容器,在该容器中存储了很多的水。那么什么是线程池呢?线程池也是可以看做成一个池子,在该池子中存储很多个线程。
线程池存在的意义:
系统创建一个线程的成本是比较高的,因为它涉及到与操作系统交互,当程序中需要创建大量生存期很短暂的线程时,频繁的创建和销毁线程对系统的资源消耗有可能大于业务处理是对系
统资源的消耗,这样就有点”舍本逐末”了。针对这一种情况,为了提高性能,我们就可以采用线程池。线程池在启动的时,会创建大量空闲线程,当我们向线程池提交任务的时,线程池就
会启动一个线程来执行该任务。等待任务执行完毕以后,线程并不会死亡,而是再次返回到线程池中称为空闲状态。等待下一次任务的执行。
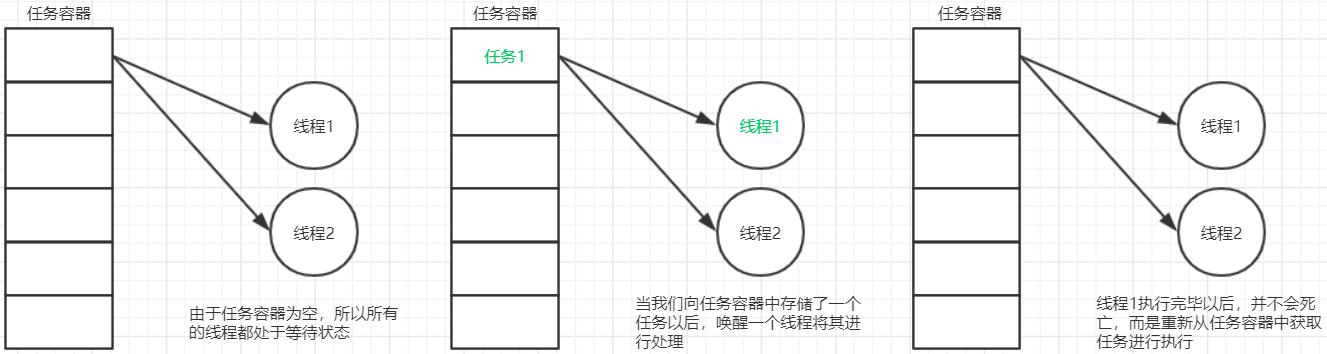
2.2 自定义线程池 2.2.1 线程池的设计思路 线程池的思路和生产者消费者模型是很接近的
准备一个任务容器
一次性启动多个(2个)消费者线程
刚开始任务容器是空的,所以线程都在wait
直到一个外部线程向这个任务容器中扔了一个”任务”,就会有一个消费者线程被唤醒
这个消费者线程取出”任务”,并且执行这个任务,执行完毕后,继续等待下一次任务的到来
在整个过程中,都不需要创建新的线程,而是循环使用这些已经存在的线程。
2.2.2 代码实现 实现思路:
创建一个线程池类(ThreadPool)
在该类中定义两个成员变量poolSize(线程池初始化线程的个数) , BlockingQueue(任务容器)
通过构造方法来创建两个线程对象(消费者线程),并且启动
使用内部类的方式去定义一个线程类(TaskThread),可以提供一个构造方法用来初始化线程名称
两个消费者线程需要不断的从任务容器中获取任务,如果没有任务,则线程处于阻塞状态。
提供一个方法(submit)向任务容器中添加任务
定义测试类进行测试
线程池类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 public class ThreadPool { private static final int DEFAULT_POOL_SIZE = 2 ; private int poolSize = DEFAULT_POOL_SIZE ; private BlockingQueue<Runnable> blockingQueue = new LinkedBlockingQueue <Runnable>() ; public ThreadPool () { this .initThread(); } public ThreadPool (int poolSize) { if (poolSize > 0 ) { this .poolSize = poolSize ; } this .initThread(); } public void initThread () { for (int x = 0 ; x < poolSize ; x++) { new TaskThread ("线程--->" + x).start(); } } public void submit (Runnable runnable) { try { blockingQueue.put(runnable); } catch (InterruptedException e) { e.printStackTrace(); } } public class TaskThread extends Thread { public TaskThread (String name) { super (name); } @Override public void run () { while (true ) { try { Runnable task = blockingQueue.take(); task.run(); } catch (InterruptedException e) { e.printStackTrace(); } } } } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class ThreadPoolDemo01 { public static void main (String[] args) { ThreadPool threadPool = new ThreadPool (5 ); for (int x = 0 ; x < 10 ; x++) { threadPool.submit( () -> { System.out.println(Thread.currentThread().getName() + "---->>>处理了任务" ); }); } } }
使用无参构造方法创建线程池对象,控制台输出结果
1 2 3 4 5 6 7 8 9 10 线程--->0 ---->>>处理了任务 线程--->1 ---->>>处理了任务 线程--->0 ---->>>处理了任务 线程--->1 ---->>>处理了任务 线程--->0 ---->>>处理了任务 线程--->1 ---->>>处理了任务 线程--->0 ---->>>处理了任务 线程--->1 ---->>>处理了任务 线程--->0 ---->>>处理了任务 线程--->1 ---->>>处理了任务
通过控制台的输出,我们可以看到在线程池中存在两个线程,通过这2个线程处理了10个任务。
使用有参构造方法创建线程池对象,传递的参数是5,控制台输出结果
1 2 3 4 5 6 7 8 9 10 线程--->3---->>>处理了任务 线程--->4---->>>处理了任务 线程--->2---->>>处理了任务 线程--->0---->>>处理了任务 线程--->2---->>>处理了任务 线程--->4---->>>处理了任务 线程--->3---->>>处理了任务 线程--->1---->>>处理了任务 线程--->2---->>>处理了任务 线程--->0---->>>处理了任务
通过控制台的输出,我们可以看到在线程池中存在两个线程,通过这5个线程处理了10个任务。
2.3 JDK中线程池 2.3.1 Executors JDK对线程池也进行了相关的实现,在真实企业开发中我们也很少去自定义线程池,而是使用JDK中自带的线程池。
我们可以使用Executors中所提供的静态 方法来创建线程池。
获取线程池的方法
//通过不同的方法创建出来的线程池具有不同的特点。
1 2 3 4 5 6 ExecutorService newCachedThreadPool () : 创建一个可缓存线程池,可灵活的去创建线程,并且灵活的回收线程,若无可回收,则新建线程。 ExecutorService newFixedThreadPool (int nThreads) : 初始化一个具有固定数量线程的线程池 ExecutorService newSingleThreadExecutor () : 初始化一个具有一个线程的线程池 ScheduledExecutorService newSingleThreadScheduledExecutor () : 初始化一个具有一个线程的线程池,支持定时及周期性任务执行
这个方法返回的都是ExecutorService类型的对象(ScheduledExecutorService继承ExecutorService),而ExecutorService可以看做就是一个线程池,那么ExecutorService
给我们提供了哪些方法供我们使用呢?
ExecutorService中的常见方法
1 2 Future<?> submit(Runnable task): 提交任务方法 void shutdown () : 关闭线程池的方法
案例1
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class ExecutorsDemo01 { public static void main (String[] args) throws InterruptedException { ExecutorService threadPool = Executors.newCachedThreadPool(); threadPool.submit(() -> { System.out.println( Thread.currentThread().getName() + "---执行了任务" ); }); threadPool.submit(() -> { System.out.println( Thread.currentThread().getName() + "---执行了任务" ); }); threadPool.shutdown(); } }
控制台输出结果
1 2 pool-1 -thread-2 ---执行了任务 pool-1 -thread-1 ---执行了任务
针对每一个任务,线程池为其分配一个线程去执行,我们可以在第二次提交任务的时候,让主线程休眠一小会儿,看程序的执行结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class ExecutorsDemo02 { public static void main (String[] args) throws InterruptedException { ExecutorService threadPool = Executors.newCachedThreadPool(); threadPool.submit(() -> { System.out.println( Thread.currentThread().getName() + "---执行了任务" ); }); TimeUnit.SECONDS.sleep(2 ); threadPool.submit(() -> { System.out.println( Thread.currentThread().getName() + "---执行了任务" ); }); threadPool.shutdown(); } }
控制台输出结果
1 2 pool-1 -thread-1 ---执行了任务 pool-1 -thread-1 ---执行了任务
我们发现是通过一个线程执行了两个任务。此时就说明线程池中的线程”pool-1-thread-1”被线程池回收了,成为了空闲线程,当我们再次提交任务的时候,该线程就去执行新的任务。
案例2
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class ExecutorsDemo03 { public static void main (String[] args) { ExecutorService threadPool = Executors.newFixedThreadPool(3 ); for (int x = 0 ; x < 5 ; x++) { threadPool.submit( () -> { System.out.println(Thread.currentThread().getName() + "----->>>执行了任务" ); }); } threadPool.shutdown(); } }
控制台输出结果
1 2 3 4 5 pool-1 -thread-1 ----->>>执行了任务 pool-1 -thread-2 ----->>>执行了任务 pool-1 -thread-2 ----->>>执行了任务 pool-1 -thread-2 ----->>>执行了任务 pool-1 -thread-3 ----->>>执行了任务
通过控制台的输出结果,我们可以看到5个任务是通过3个线程进行执行的,说明此线程池中存在三个线程对象
案例3
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class ExecutorsDemo04 { public static void main (String[] args) { ExecutorService threadPool = Executors.newSingleThreadExecutor(); for (int x = 0 ; x < 5 ; x++) { threadPool.submit(() -> { System.out.println(Thread.currentThread().getName() + "----->>>执行了任务" ); }); } threadPool.shutdown(); } }
控制台输出结果
1 2 3 4 5 pool-1 -thread-1 ----->>>执行了任务 pool-1 -thread-1 ----->>>执行了任务 pool-1 -thread-1 ----->>>执行了任务 pool-1 -thread-1 ----->>>执行了任务 pool-1 -thread-1 ----->>>执行了任务
通过控制台的输出结果,我们可以看到5个任务是通过1个线程进行执行的,说明此线程池中只存在一个线程对象。
案例4
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class ExecutorsDemo05 { public static void main (String[] args) { ScheduledExecutorService threadPool = Executors.newSingleThreadScheduledExecutor(); for (int x = 0 ; x < 5 ; x++) { threadPool.submit(() -> { System.out.println(Thread.currentThread().getName() + "---->>执行了任务" ); }); } threadPool.shutdown(); } }
控制台输出结果
1 2 3 4 5 pool-1 -thread-1 ---->>执行了任务 pool-1 -thread-1 ---->>执行了任务 pool-1 -thread-1 ---->>执行了任务 pool-1 -thread-1 ---->>执行了任务 pool-1 -thread-1 ---->>执行了任务
通过控制台的输出结果,我们可以看到5个任务是通过1个线程进行执行的,说明此线程池中只存在一个线程对象。
案例5
ScheduledExecutorService中和定时以及周期性执行相关的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public ScheduledFuture<?> schedule(Runnable command,long delay, TimeUnit unit);public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit);
测试类1(演示定时执行)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class ExecutorsDemo06 { public static void main (String[] args) { ScheduledExecutorService threadPool = Executors.newSingleThreadScheduledExecutor(); threadPool.schedule( () -> { System.out.println(Thread.currentThread().getName() + "---->>>执行了该任务" ); } , 10 , TimeUnit.SECONDS) ; threadPool.shutdown(); } }
测试类2(演示周期性执行)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class ExecutorsDemo07 { public static void main (String[] args) { ScheduledExecutorService threadPool = Executors.newSingleThreadScheduledExecutor(); threadPool.scheduleAtFixedRate( () -> { System.out.println(Thread.currentThread().getName() + "---->>>执行了该任务" ); } , 10 ,1 , TimeUnit.SECONDS) ; } }
2.3.2 ThreadPoolExecutor 1) 基本使用 刚才我们是通过Executors中的静态方法去创建线程池的,通过查看源代码我们发现,其底层都是通过ThreadPoolExecutor构建的。比如:newFixedThreadPool方法的源码
1 2 3 4 5 public static ExecutorService newFixedThreadPool (int nThreads) { return new ThreadPoolExecutor (nThreads, nThreads,0L , TimeUnit.MILLISECONDS, new LinkedBlockingQueue <Runnable>()); }
那么也可以使用ThreadPoolExecutor去创建线程池。
ThreadPoolExecutor最完整的构造方法:
1 2 3 4 5 6 7 public ThreadPoolExecutor (int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
参数说明
1 2 3 4 5 6 7 corePoolSize: 核心线程的最大值,不能小于0 maximumPoolSize:最大线程数,不能小于等于0 ,maximumPoolSize >= corePoolSize keepAliveTime: 空闲线程最大存活时间,不能小于0 unit: 时间单位 workQueue: 任务队列,不能为null threadFactory: 创建线程工厂,不能为null handler: 任务的拒绝策略,不能为null
案例演示通过ThreadPoolExecutor创建线程池
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class ThreadPoolExecutorDemo01 { public static void main (String[] args) { ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor (1 , 3 , 60 , TimeUnit.SECONDS , new ArrayBlockingQueue <Runnable>(3 ) , Executors.defaultThreadFactory() , new ThreadPoolExecutor .AbortPolicy()) ; threadPoolExecutor.submit( () -> { System.out.println(Thread.currentThread().getName() + "------>>>执行了任务" ); }); threadPoolExecutor.shutdown(); } }
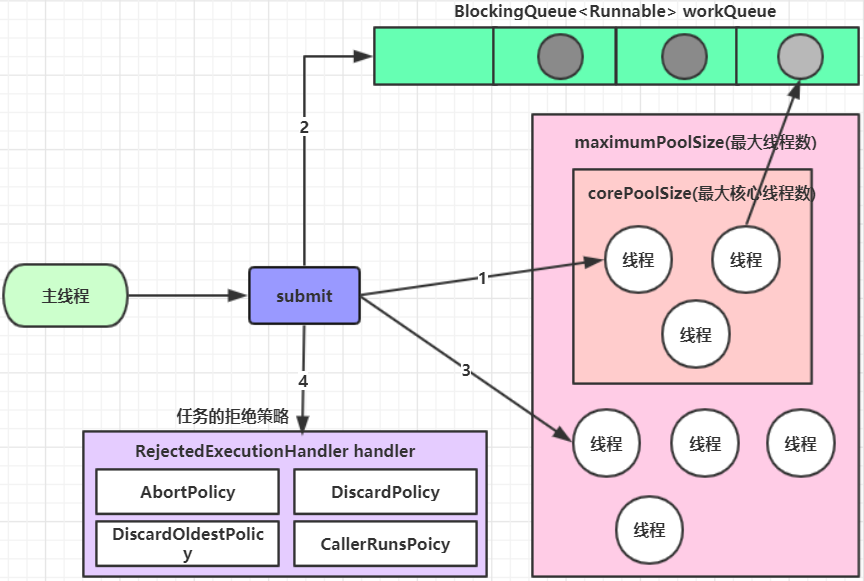
2) 工作原理 接下来我们就来研究一下线程池的工作原理,如下图所示
当我们通过submit方法向线程池中提交任务的时候,具体的工作流程如下:
客户端每次提交一个任务,线程池就会在核心线程池中创建一个工作线程来执行这个任务。当核心线程池中的线程已满时,则进入下一步操作。
把任务试图存储到工作队列中。如果工作队列没有满,则将新提交的任务存储在这个工作队列里,等待核心线程池中的空闲线程执行。如果工作队列满了,则进入下个流程。
线程池会再次在非核心线程池区域去创建新工作线程来执行任务,直到当前线程池总线程数量超过最大线程数时,就是按照指定的任务处理策略处理多余的任务。
举例说明:
假如有一个工厂,工厂里面有10个工人(正式员工),每个工人同时只能做一件任务。因此只要当10个工人中有工人是空闲的,来了任务就分配给空闲的工人做;当10个工人都有任务在做时,
如果还来了任务,就把任务进行排队等待;如果说新任务数目增长的速度远远大于工人做任务的速度,那么此时工厂主管可能会想补救措施,比如重新招4个临时工人进来;然后就将任务也分配
给这4个临时工人做;如果说着14个工人做任务的速度还是不够,此时工厂主管可能就要考虑不再接收新的任务或者抛弃前面的一些任务了。当这14个工人当中有人空闲时,而新任务增长的速度
又比较缓慢,工厂主管可能就考虑辞掉4个临时工了,只保持原来的10个工人,毕竟请额外的工人是要花钱的。
这里的工厂可以看做成是一个线程池,每一个工人可以看做成是一个线程。其中10个正式员工,可以看做成是核心线程池中的线程,临时工就是非核心线程池中的线程。当临时工处于空闲状态
的时候,那么如果空闲的时间超过keepAliveTime所指定的时间,那么就会被销毁。
3) 案例演示 接下来我们就通过一段代码的断点测试,来演示一下线程池的工作原理。
案例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class ThreadPoolExecutorDemo01 { public static void main (String[] args) { ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor (1 , 3 , 20 , TimeUnit.SECONDS , new ArrayBlockingQueue <>(1 ) , Executors.defaultThreadFactory() , new ThreadPoolExecutor .AbortPolicy()) ; for (int x = 0 ; x < 3 ; x++) { threadPoolExecutor.submit(() -> { System.out.println(Thread.currentThread().getName() + "---->> 执行了任务" ); }); } } }
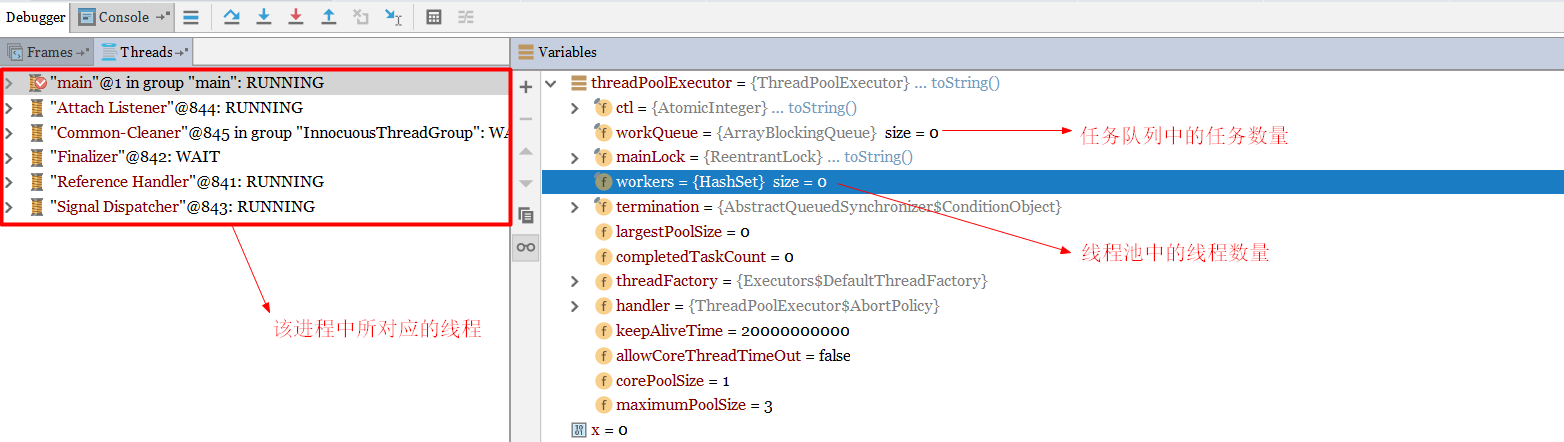
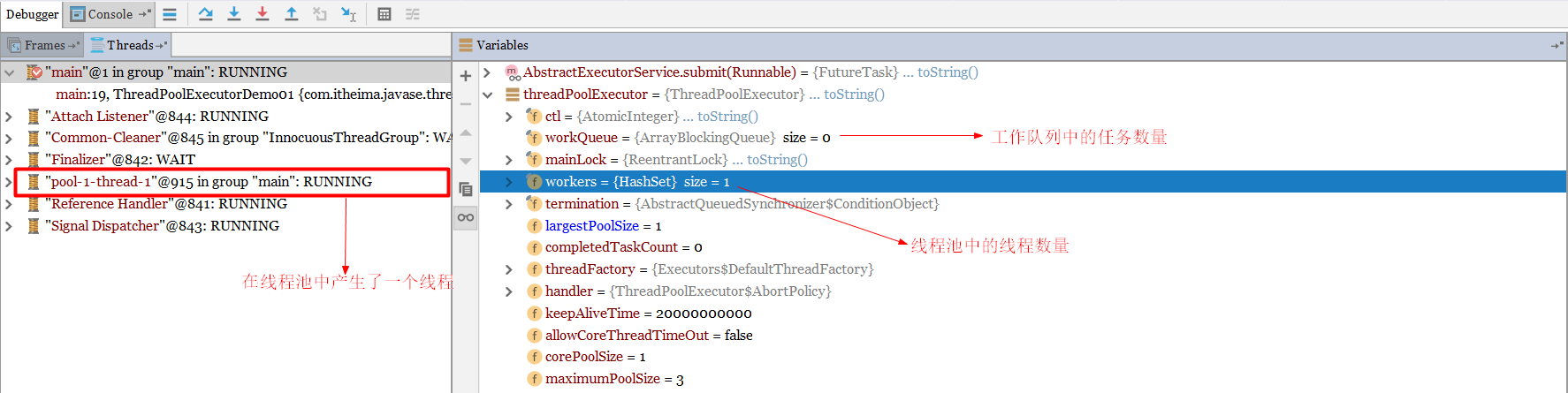
初次debug方式启动线程,查看变量值
由于此时还没有提交任务,因此线程池中的线程数量为0,工作队列的任务数量也为0;提交一个任务
再次查看各个值的变化
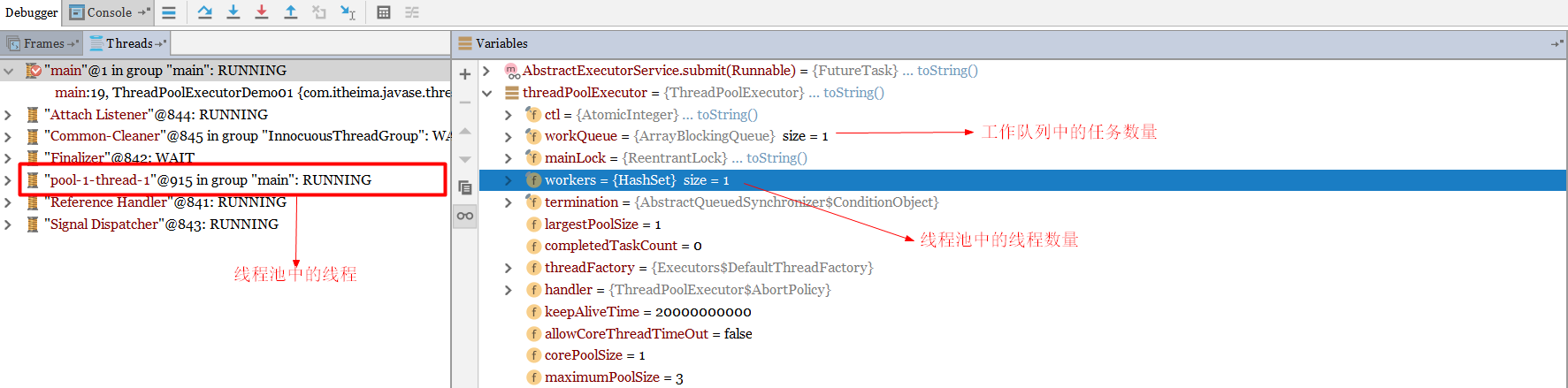
再次提交一个任务
再次查看各个值的变化
此时会把第二个任务存储到工作队列中,因此工作队列的值为1了。再次提交一个任务
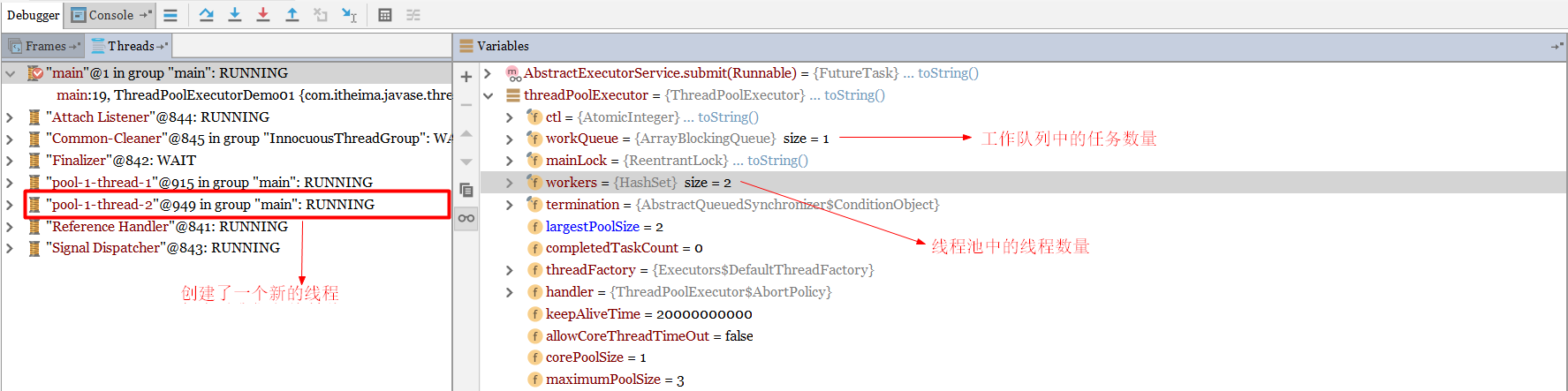
再次查看各个值的变化
此时3个任务都以及提交完毕,断点跳过。经过20s以后,再次查看该进程中的线程。
我们发现非核心线程已经被线程池回收了。
4) 任务拒绝策略 RejectedExecutionHandler是jdk提供的一个任务拒绝策略接口,它下面存在4个子类。
1 2 3 4 ThreadPoolExecutor.AbortPolicy: 丢弃任务并抛出RejectedExecutionException异常。是默认的策略。 ThreadPoolExecutor.DiscardPolicy: 丢弃任务,但是不抛出异常 这是不推荐的做法。 ThreadPoolExecutor.DiscardOldestPolicy: 抛弃队列中等待最久的任务 然后把当前任务加入队列中。 ThreadPoolExecutor.CallerRunsPolicy: 调用任务的run()方法绕过线程池直接执行。
注:明确线程池对多可执行的任务数 = 队列容量 + 最大线程数
案例演示1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class ThreadPoolExecutorDemo01 { public static void main (String[] args) { ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor (1 , 3 , 20 , TimeUnit.SECONDS , new ArrayBlockingQueue <>(1 ) , Executors.defaultThreadFactory() , new ThreadPoolExecutor .AbortPolicy()) ; for (int x = 0 ; x < 5 ; x++) { threadPoolExecutor.submit(() -> { System.out.println(Thread.currentThread().getName() + "---->> 执行了任务" ); }); } } }
控制台输出结果
1 2 3 4 5 6 7 8 9 10 Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task java.util.concurrent.FutureTask@566776ad[Not completed, task = java.util.concurrent.Executors$RunnableAdapter@edf4efb [Wrapped task = com.itheima.javase.thread.pool.demo04.ThreadPoolExecutorDemo01$$Lambda$14 /0x0000000100066840 @2f7a2457]] rejected from java.util.concurrent.ThreadPoolExecutor@6108b2d7[Running, pool size = 3 , active threads = 3 , queued tasks = 1 , completed tasks = 0 ] at java.base/java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2055 ) at java.base/java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:825 ) at java.base/java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1355 ) at java.base/java.util.concurrent.AbstractExecutorService.submit(AbstractExecutorService.java:118 ) at com.itheima.javase.thread.pool.demo04.ThreadPoolExecutorDemo01.main(ThreadPoolExecutorDemo01.java:20 ) pool-1 -thread-1 ---->> 执行了任务 pool-1 -thread-3 ---->> 执行了任务 pool-1 -thread-2 ---->> 执行了任务 pool-1 -thread-3 ---->> 执行了任务
控制台报错,仅仅执行了4个任务,有一个任务被丢弃了
案例演示2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class ThreadPoolExecutorDemo02 { public static void main (String[] args) { ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor (1 , 3 , 20 , TimeUnit.SECONDS , new ArrayBlockingQueue <>(1 ) , Executors.defaultThreadFactory() , new ThreadPoolExecutor .DiscardPolicy()) ; for (int x = 0 ; x < 5 ; x++) { threadPoolExecutor.submit(() -> { System.out.println(Thread.currentThread().getName() + "---->> 执行了任务" ); }); } } }
控制台输出结果
1 2 3 4 pool-1 -thread-1 ---->> 执行了任务 pool-1 -thread-1 ---->> 执行了任务 pool-1 -thread-3 ---->> 执行了任务 pool-1 -thread-2 ---->> 执行了任务
控制台没有报错,仅仅执行了4个任务,有一个任务被丢弃了
案例演示3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class ThreadPoolExecutorDemo02 { public static void main (String[] args) { ThreadPoolExecutor threadPoolExecutor; threadPoolExecutor = new ThreadPoolExecutor (1 , 3 , 20 , TimeUnit.SECONDS , new ArrayBlockingQueue <>(1 ) , Executors.defaultThreadFactory() , new ThreadPoolExecutor .DiscardOldestPolicy()); for (int x = 0 ; x < 5 ; x++) { final int y = x ; threadPoolExecutor.submit(() -> { System.out.println(Thread.currentThread().getName() + "---->> 执行了任务" + y); }); } } }
控制台输出结果
1 2 3 4 pool-1 -thread-2 ---->> 执行了任务2 pool-1 -thread-1 ---->> 执行了任务0 pool-1 -thread-3 ---->> 执行了任务3 pool-1 -thread-1 ---->> 执行了任务4
由于任务1在线程池中等待时间最长,因此任务1被丢弃。
案例演示4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class ThreadPoolExecutorDemo04 { public static void main (String[] args) { ThreadPoolExecutor threadPoolExecutor; threadPoolExecutor = new ThreadPoolExecutor (1 , 3 , 20 , TimeUnit.SECONDS , new ArrayBlockingQueue <>(1 ) , Executors.defaultThreadFactory() , new ThreadPoolExecutor .CallerRunsPolicy()); for (int x = 0 ; x < 5 ; x++) { threadPoolExecutor.submit(() -> { System.out.println(Thread.currentThread().getName() + "---->> 执行了任务" ); }); } } }
控制台输出结果
1 2 3 4 5 pool-1 -thread-1 ---->> 执行了任务 pool-1 -thread-3 ---->> 执行了任务 pool-1 -thread-2 ---->> 执行了任务 pool-1 -thread-1 ---->> 执行了任务 main---->> 执行了任务
通过控制台的输出,我们可以看到次策略没有通过线程池中的线程执行任务,而是直接调用任务的run()方法绕过线程池直接执行。
3 volatile关键字 3.1 看程序说结果 分析如下程序,说出在控制台的输出结果。
Thread的子类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class VolatileThread extends Thread { private boolean flag = false ; public boolean isFlag () { return flag;} @Override public void run () { try { Thread.sleep(1000 ); } catch (InterruptedException e) { e.printStackTrace(); } this .flag = true ; System.out.println("flag=" + flag); } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class VolatileThreadDemo01 { public static void main (String[] args) { VolatileThread volatileThread = new VolatileThread () ; volatileThread.start(); while (true ) { System.out.println("main线程中获取开启的线程中flag的值为" + volatileThread.isFlag()); } } }
控制台输出结果
1 前面是false ,过了一段时间之后就变成了true
按照我们的分析,当我们把volatileThread线程启动起来以后,那么volatileThread线程开始执行。在volatileThread线程的run方法中,线程休眠1s,休眠一秒以后那么flag的值应该为
true,此时我们在主线程中不停的获取flag的值。发现前面释放false,后面是true
信息,那么这是为什么呢?要想知道原因,那么我们就需要学习一下JMM。
3.2 JMM 概述:JMM(Java Memory Model)Java内存模型,是java虚拟机规范中所定义的一种内存模型。
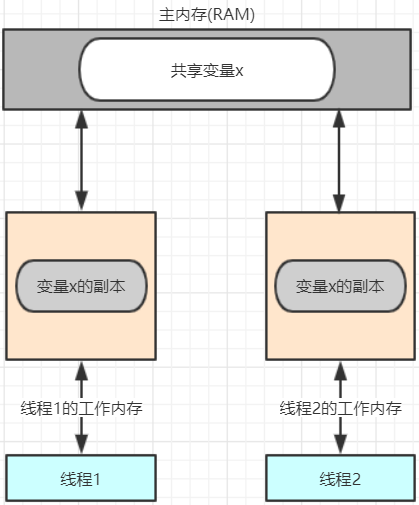
Java内存模型(Java Memory Model)描述了Java程序中各种变量(线程共享变量)的访问规则,以及在JVM中将变量存储到内存和从内存中读取变量这样的底层细节。
特点:
所有的共享变量都存储于主内存(计算机的RAM)这里所说的变量指的是实例变量和类变量。不包含局部变量,因为局部变量是线程私有的,因此不存在竞争问题。
每一个线程还存在自己的工作内存,线程的工作内存,保留了被线程使用的变量的工作副本。
线程对变量的所有的操作(读,写)都必须在工作内存中完成,而不能直接读写主内存中的变量,不同线程之间也不能直接访问对方工作内存中的变量,线程间变量的值的传递需要通过主
内存完成。
3.3 问题分析 了解了一下JMM,那么接下来我们就来分析一下上述程序产生问题的原因。
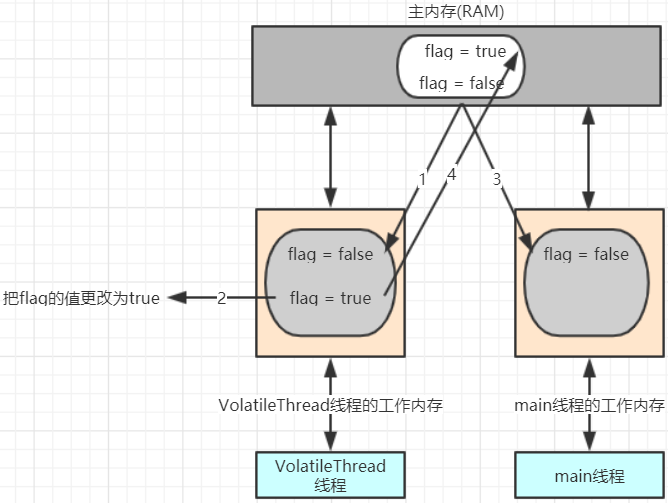
产生问题的流程分析:
VolatileThread线程从主内存读取到数据放入其对应的工作内存
将flag的值更改为true,但是这个时候flag的值还没有回写主内存
此时main线程读取到了flag的值并将其放入到自己的工作内存中,此时flag的值为false
VolatileThread线程将flag的值写回到主内存,但是main函数里面的while(true)调用的是系统比较底层的代码,速度快,快到没有时间再去读取主内存中的值,所以while(true)
读取到的值一直是false。(如果有一个时刻main线程从主内存中读取到了flag的最新值,那么if语句就可以执行,main线程何时从主内存中读取最新的值,我们无法控制)
我们可以让主线程执行慢一点,执行慢一点以后,在某一个时刻,可能就会读取到主内存中最新的flag的值,那么if语句就可以进行执行。
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class VolatileThreadDemo02 { public static void main (String[] args) throws InterruptedException { VolatileThread volatileThread = new VolatileThread () ; volatileThread.start(); while (true ) { if (volatileThread.isFlag()) { System.out.println("执行了======" ); } TimeUnit.MILLISECONDS.sleep(100 ); } } }
控制台输出结果
1 2 3 4 5 flag=true 执行了====== 执行了====== 执行了====== ....
此时我们可以看到if语句已经执行了。当然我们在真实开发中可能不能使用这种方式来处理这个问题,那么这个问题应该怎么处理呢?我们就需要学习下一小节的内容。
3.4 问题处理 3.4.1 加锁 第一种处理方案,我们可以通过加锁的方式进行处理。
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class VolatileThreadDemo03 { public static void main (String[] args) throws InterruptedException { VolatileThread volatileThread = new VolatileThread () ; volatileThread.start(); while (true ) { synchronized (volatileThread) { if (volatileThread.isFlag()) { System.out.println("执行了======" ); } } } } }
控制台输出结果
1 2 3 4 5 flag=true 执行了====== 执行了====== 执行了====== ....
工作原理说明
对上述代码加锁完毕以后,某一个线程支持该程序的过程如下:
a.线程获得锁
b.清空工作内存
c.从主内存拷贝共享变量最新的值到工作内存成为副本
d.执行代码
e.将修改后的副本的值刷新回主内存中
f.线程释放锁
3.4.2 volatile关键字 第二种处理方案,我们可以通过volatile关键字来修饰flag变量。
线程类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public class VolatileThread extends Thread { private volatile boolean flag = false ; public boolean isFlag () { return flag;} @Override public void run () { try { Thread.sleep(1000 ); } catch (InterruptedException e) { e.printStackTrace(); } this .flag = true ; System.out.println("flag=" + flag); } } public class VolatileTest extends Thread { boolean flag = false ; int i = 0 ; public void run () { while (!flag) { i++; } System.out.println("stope" + i); } public static void main (String[] args) throws Exception { VolatileTest vt = new VolatileTest (); vt.start(); Thread.sleep(10 ); vt.flag = true ; } }
控制台输出结果
1 2 3 4 5 flag=true 执行了====== 执行了====== 执行了====== ....
工作原理说明
执行流程分析
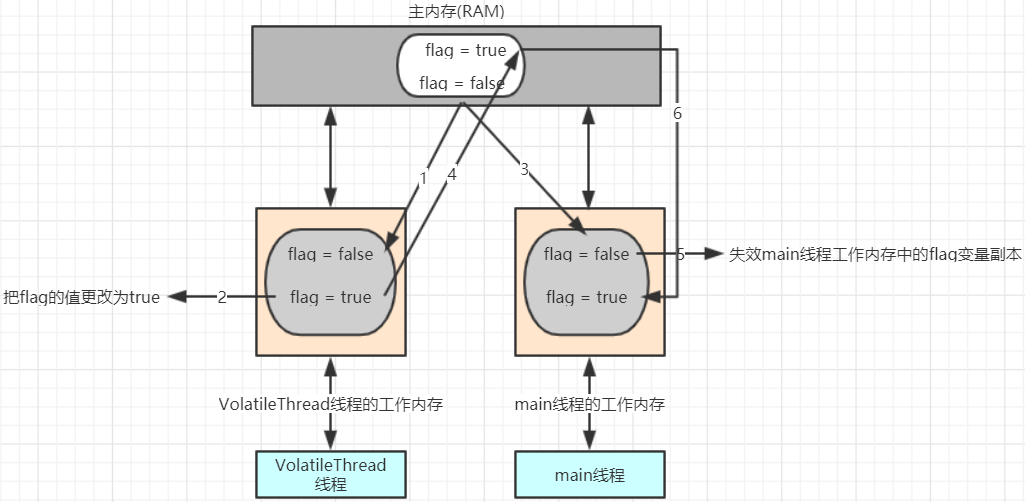
VolatileThread线程从主内存读取到数据放入其对应的工作内存
将flag的值更改为true,但是这个时候flag的值还没有回写主内存
此时main线程读取到了flag的值并将其放入到自己的工作内存中,此时flag的值为false
VolatileThread线程将flag的值写到主内存
main线程工作内存中的flag变量副本失效
main线程再次使用flag时,main线程会从主内存读取最新的值,放入到工作内存中,然后在进行使用
总结: volatile保证不同线程对共享变量操作的可见性,也就是说一个线程修改了volatile修饰的变量,当修改写回主内存时,另外一个线程立即看到最新的值。
但是volatile不保证原子性(关于原子性问题,我们在下面的小节中会介绍)。
volatile与synchronized的区别:
volatile只能修饰实例变量和类变量,而synchronized可以修饰方法,以及代码块。
volatile保证数据的可见性,但是不保证原子性(多线程进行写操作,不保证线程安全);而synchronized是一种排他(互斥)的机制(因此有时我们也将synchronized这种锁称
之为排他(互斥)锁),synchronized修饰的代码块,被修饰的代码块称之为同步代码块,无法被中断可以保证原子性,也可以间接的保证可见性。
4 原子性 概述:所谓的原子性是指在一次操作或者多次操作中,要么所有的操作全部都得到了执行并且不会受到任何因素的干扰而中断,要么所有的操作都不执行,多个操作是一个不可以分割的整体。
//比如说:你喂你女朋友吃冰淇淋,如果没有女朋友,你就假想一下,实在不行,你就喂你旁边的哥们吃一口冰淇淋。这就是一个不可分割的整体,一个是你喂,一个是她吃。这就是一个整体,如果没有她吃,那么你喂就没有意义,如果没有你喂,她吃就没有意义。
//比如:从张三的账户给李四的账户转1000元,这个动作将包含两个基本的操作:从张三的账户扣除1000元,给李四的账户增加1000元。这两个操作必须符合原子性的要求,要么都成功要么
都失败。
4.1 看程序说结果 分析如下程序的执行结果
线程类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class VolatileAtomicThread implements Runnable { private int count = 0 ; @Override public void run () { for (int x = 0 ; x < 100 ; x++) { count++ ; System.out.println("冰淇淋的个数 =========>>>> " + count); } } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class VolatileAtomicThreadDemo { public static void main (String[] args) { VolatileAtomicThread volatileAtomicThread = new VolatileAtomicThread () ; for (int x = 0 ; x < 100 ; x++) { new Thread (volatileAtomicThread).start(); } } }
程序分析:我们在主线程中通过for循环启动了100个线程,每一个线程都会对VolatileAtomicThread类中的count加100次。那么直接结果应该是10000。但是真正的执行结果和我们分析
的是否一样呢?运行程序(多运行几次),查看控制台输出结果
1 2 3 4 .... count =========>>>> 9997 count =========>>>> 9998 count =========>>>> 9999
通过控制台的输出,我们可以看到最终count的结果可能并不是10000。接下来我们就来分析一下问题产生的原因。
4.2 问题分析说明 以上问题主要是发生在count++操作上:
count++操作包含3个步骤:
从主内存中读取数据到工作内存
对工作内存中的数据进行++操作
将工作内存中的数据写回到主内存
count++操作不是一个原子性操作,也就是说在某一个时刻对某一个操作的执行,有可能被其他的线程打断。
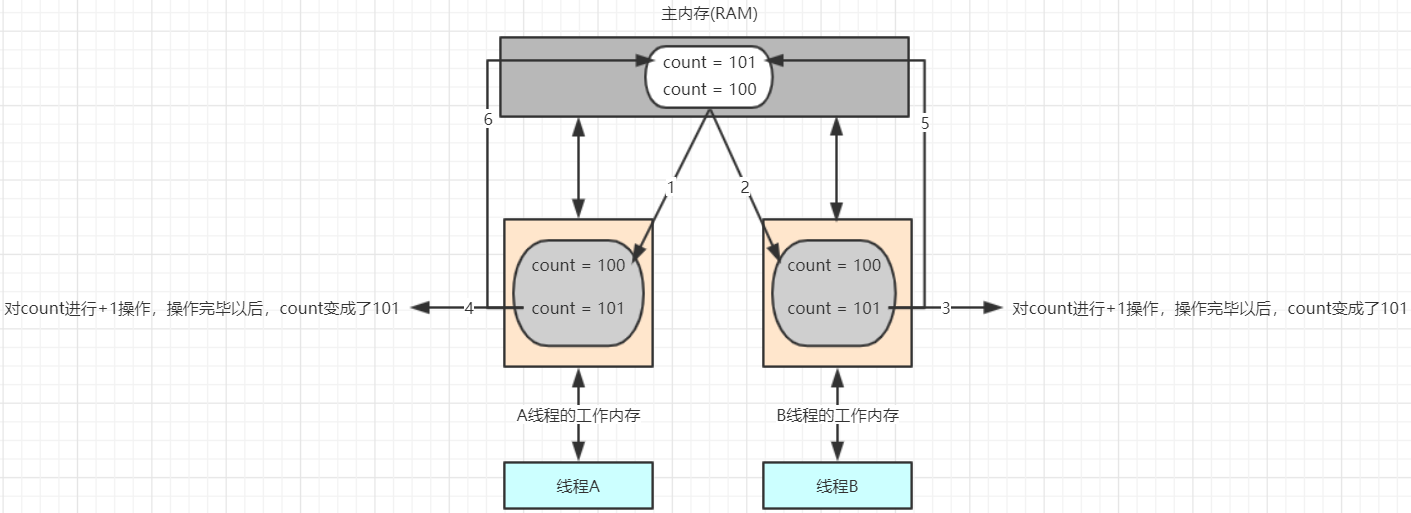
产生问题的执行流程分析:
假设此时count的值是100,线程A需要对改变量进行自增1的操作,首先它需要从主内存中读取变量count的值。由于CPU的切换关系,此时CPU的执行权被切换到了B线程。A线程就处
于就绪状态,B线程处于运行状态。
线程B也需要从主内存中读取count变量的值,由于线程A没有对count值做任何修改因此此时B读取到的数据还是100
线程B工作内存中对count执行了+1操作,但是未刷新之主内存中
此时CPU的执行权切换到了A线程上,由于此时线程B没有将工作内存中的数据刷新到主内存,因此A线程工作内存中的变量值还是100,没有失效。A线程对工作内存中的数据进行了+1操作。
线程B将101写入到主内存
线程A将101写入到主内存
虽然计算了2次,但是只对A进行了1次修改。
4.3 volatile原子性测试 我们刚才说到了volatile在多线程环境下只保证了共享变量在多个线程间的可见性,但是不保证原子性。那么接下来我们就来做一个测试。测试的思想,就是使用volatile修饰count。
线程类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class VolatileAtomicThread implements Runnable { private volatile int count = 0 ; @Override public void run () { for (int x = 0 ; x < 100 ; x++) { count++ ; System.out.println("count =========>>>> " + count); } } }
控制台输出结果(需要运行多次)
1 2 3 4 ... count =========>>>> 9997 count =========>>>> 9998 count =========>>>> 9999
通过控制台结果的输出,我们可以看到程序还是会出现问题。因此也就证明volatile关键字是不保证原子性的。
4.4 volatile使用场景 volatile关键字不保证原子性操作,那么同学们可能会存在一些疑问,volatile关键字在什么情况下进行使用呢?这里我们举两个基本的使用场景。
4.4.1 状态标志 比如现在存在一个线程不断向控制台输出一段话”传智播客中国IT教育的标杆….”,当这个线程执行5秒以后,将该线程结束。
实现思路:定义一个boolean类型的变量,这个变量就相当于一个标志。当这个变量的值为true的时候,线程一直执行,10秒以后我们把这个变量的值更改为false,此时结束该线程的执行。
为了保证一个线程对这个变量的修改,另外一个线程立马可以看到,这个变量就需要通过volatile关键字进行修饰。
线程类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class VolatileUseThread implements Runnable { private volatile boolean shutdown = false ; @Override public void run () { while (!shutdown) { System.out.println("传智播客中国IT教育的标杆...." ); } } public void shutdown () { this .shutdown = true ; } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class VolatileUseThreadDemo01 { public static void main (String[] args) throws InterruptedException { VolatileUseThread volatileUseThread = new VolatileUseThread () ; Thread thread = new Thread (volatileUseThread); thread.start(); TimeUnit.SECONDS.sleep(5 ); volatileUseThread.shutdown(); } }
观察控制台输出,volatileUseThread线程执行5秒以后程序结束。
4.4.2 独立观察 //AI养猪。。。。
//设备区测量温度
//当温度高了。。。需要给猪开空调。。。加冰棍。。。加喝的水。。。
volatile的另一种简单使用场景是:定期”发布”观察结果供程序内部使用。例如,假设有一种环境传感器能够感觉环境温度。一个后台线程可能会每隔几秒读取一次该传感器数据,并更新包
含这个volatile变量的值。然后,其他线程可以读取这个变量,从而随时能够看到最新的温度值。这种使用就是多个线程操作共享变量,但是是有一个线程对其进行写操作,其他的线程都是读。
我们可以设计一个程序,模拟上面的温度传感器案例。
实现步说明
定义一个温度传感器(TemperatureSensor)的类,在该类中定义两个成员变量(temperature(温度值),type(传感器的类型)),temperature变量需要被volatile修饰
定义一个读取温度传感器的线程的任务类(ReadTemperatureRunnable),该类需要定义一个TemperatureSensor类型的成员变量(该线程需要读取温度传感器的数据)
定义一个定时采集温度的线程任务类(GatherTemperatureRunnable),该类需要定义一个TemperatureSensor类型的成员变量(该线程需要将读到的温度设置给传感器)
创建测试类(TemperatureSensorDemo)
创建TemperatureSensor对象
创建ReadTemperatureRunnable类对象,把TemperatureSensor作为构造方法的参数传递过来
创建GatherTemperatureRunnable类对象,把TemperatureSensor作为构造方法的参数传递过来
创建2个Thread对象,并启动,把第二步所创建的对象作为构造方法参数传递过来,这两个线程负责读取TemperatureSensor中的温度数据
创建1个Thread对象,并启动,把第三步所创建的对象作为构造方法参数传递过来,这个线程负责读取定时采集数据中的温度数据
TemperatureSensor类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class TemperatureSensor { private volatile int temperature ; private String type ; public int getTemperature () { return temperature; } public void setTemperature (int temperature) { this .temperature = temperature; } public String getType () { return type; } public void setType (String type) { this .type = type; } }
ReadTemperatureRunnable类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class ReadTemperatureRunnable implements Runnable { private TemperatureSensor temperatureSensor ; public ReadTemperatureRunnable (TemperatureSensor temperatureSensor) { this .temperatureSensor = temperatureSensor ; } @Override public void run () { while (true ) { System.out.println(Thread.currentThread().getName() + "---读取到的温度数据为------>>> " + temperatureSensor.getTemperature()); try { TimeUnit.MILLISECONDS.sleep(100 ); } catch (InterruptedException e) { e.printStackTrace(); } } } }
GatherTemperatureRunnable类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class GatherTemperatureRunnable implements Runnable { private TemperatureSensor temperatureSensor ; public GatherTemperatureRunnable (TemperatureSensor temperatureSensor) { this .temperatureSensor = temperatureSensor ; } @Override public void run () { int temperature = 23 ; while (true ) { System.out.println(Thread.currentThread().getName() + "-----采集到的数据为----->>> " + temperature); temperatureSensor.setTemperature(temperature); try { TimeUnit.SECONDS.sleep(2 ); } catch (InterruptedException e) { e.printStackTrace(); } temperature += 2 ; } } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class TemperatureSensorDemo { public static void main (String[] args) { TemperatureSensor temperatureSensor = new TemperatureSensor (); ReadTemperatureRunnable readTemperatureRunnable = new ReadTemperatureRunnable (temperatureSensor) ; GatherTemperatureRunnable gatherTemperatureRunnable = new GatherTemperatureRunnable (temperatureSensor) ; for (int x = 0 ; x < 2 ; x++) { new Thread (readTemperatureRunnable).start(); } Thread gatherThread = new Thread (gatherTemperatureRunnable); gatherThread.setName("温度采集线程" ); gatherThread.start(); } }
控制台输出结果
1 2 3 4 5 6 7 ... 温度采集线程-----采集到的数据为----->>> 23 Thread-0 ---读取到的温度数据为------>>> 23 ... 温度采集线程-----采集到的数据为----->>> 25 Thread-1 ---读取到的温度数据为------>>> 25 ...
通过控制台的输出,我们可以看到当温度采集线程刚采集到环境温度以后,那么此时两个温度读取线程就可以立即感知到环境温度的变化。
4.5 问题处理 接下来我们就来讲解一下我们上述案例(引入原子性问题的案例)的解决方案。
4.5.1 锁机制 我们可以给count++操作添加锁,那么count++操作就是临界区中的代码,临界区中的代码一次只能被一个线程去执行,所以count++就变成了原子操作。
线程任务类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class VolatileAtomicThread implements Runnable { private int count = 0 ; private Object obj = new Object (); @Override public void run () { for (int x = 0 ; x < 100 ; x++) { synchronized (obj){ count++ ; System.out.println("count =========>>>> " + count); } } } }
控制台输出结果
1 2 3 count =========>>>> 9998 count =========>>>> 9999 count =========>>>> 10000
4.5.2 原子类 1) AtomicInteger 概述:java从JDK1.5开始提供了java.util.concurrent.atomic包(简称Atomic包),这个包中的原子操作类提供了一种用法简单,性能高效,线程安全地更新一个变量的方式。因为变
量的类型有很多种,所以在Atomic包里一共提供了13个类,属于4种类型的原子更新方式,分别是原子更新基本类型、原子更新数组、原子更新引用和原子更新属性(字段)。本次我们只讲解
使用原子的方式更新基本类型,使用原子的方式更新基本类型Atomic包提供了以下3个类:
AtomicBoolean: 原子更新布尔类型
AtomicInteger: 原子更新整型
AtomicLong: 原子更新长整型
以上3个类提供的方法几乎一模一样,所以本节仅以AtomicInteger为例进行讲解,AtomicInteger的常用方法如下:
1 2 3 4 5 6 7 8 public AtomicInteger () : 初始化一个默认值为0 的原子型Integerpublic AtomicInteger (int initialValue) : 初始化一个指定值的原子型Integerint get () : 获取值int getAndIncrement () : 以原子方式将当前值加1 ,注意,这里返回的是自增前的值。int incrementAndGet () : 以原子方式将当前值加1 ,注意,这里返回的是自增后的值。int addAndGet (int data) : 以原子方式将输入的数值与实例中的值(AtomicInteger里的value)相加,并返回结果。int getAndSet (int value) : 以原子方式设置为newValue的值,并返回旧值。
案例演示AtomicInteger的基本使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public class AtomicIntegerDemo01 { public static void main (String[] args) { AtomicInteger atomicInteger = new AtomicInteger (5 ) ; System.out.println(atomicInteger); System.out.println(atomicInteger.get()); System.out.println(atomicInteger.getAndIncrement()); System.out.println(atomicInteger.get()); System.out.println(atomicInteger.incrementAndGet()); System.out.println(atomicInteger.addAndGet(8 )); System.out.println(atomicInteger.getAndSet(20 )); System.out.println(atomicInteger.get()); } }
2) 案例改造 使用AtomicInteger对案例进行改造。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class VolatileAtomicThread implements Runnable { private AtomicInteger atomicInteger = new AtomicInteger () ; @Override public void run () { for (int x = 0 ; x < 100 ; x++) { int i = atomicInteger.incrementAndGet(); System.out.println("count =========>>>> " + i); } } }
控制台输出结果
1 2 3 4 ... count =========>>>> 9998 count =========>>>> 9999 count =========>>>> 10000
通过控制台的执行结果,我们可以看到最终得到的结果就是10000,因此也就证明AtomicInteger所提供的方法是原子性操作方法。
4.6 AtomicInteger原理 4.6.1 原理介绍 AtomicInteger的本质:自旋锁 + CAS算法
CAS的全成是: Compare And Swap(比较再交换); 是现代CPU广泛支持的一种对内存中的共享数据进行操作的一种特殊指令。CAS可以将read-modify-write转换为原子操作,这个原子操作
直接由处理器保证。CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当旧预期值A和内存值V相同时,将内存值V修改为B并返回true,否则什么都不做,并返回false。
举例说明:
在内存值V当中,存储着值为10的变量。
此时线程1想要把变量的值增加1。对线程1来说,旧的预期值 A = 10 ,要修改的新值 B = 11。
在线程1要提交更新之前,另一个线程2抢先一步,把内存值V中的变量值率先更新成了11。
线程1开始提交更新,首先进行A和内存值V的实际值比较(Compare),发现A不等于V的值,提交失败。
线程1重新获取内存值V作为当前A的值,并重新计算想要修改的新值。此时对线程1来说,A = 11,B = 12。这个重新尝试的过程被称为自旋
这一次比较幸运,没有其他线程改变V的值。线程1进行Compare,发现A和V的值是相等的。
线程1进行SWAP,把内存V的值替换为B,也就是12。
举例说明:这好比春节的时候抢火车票,下手快的会抢先买到票,而下手慢的可以再次尝试,直到买到票。
4.6.2 源码分析 那么接下来我们就来查看一下AtomicInteger类中incrementAndGet方法的源码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class AtomicInteger extends Number implements java .io.Serializable { private static final jdk.internal.misc.Unsafe U = jdk.internal.misc.Unsafe.getUnsafe(); private static final long VALUE = U.objectFieldOffset(AtomicInteger.class, "value" ); private volatile int value; public final int incrementAndGet () { return U.getAndAddInt(this , VALUE, 1 ) + 1 ; } }
UnSafe类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public final class Unsafe { public final int getAndAddInt (Object o, long offset, int delta) { int v; do { v = getIntVolatile(o, offset); } while (!weakCompareAndSetInt(o, offset, v, v + delta)); return v; } public final boolean weakCompareAndSetInt (Object o, long offset, int expected, int x) { return compareAndSetInt(o, offset, expected, x); } public final native boolean compareAndSetInt (Object o, long offset, int expected, int x) ; }
4.7 CAS与Synchronized CAS和Synchronized都可以保证多线程环境下共享数据的安全性。那么他们两者有什么区别?
Synchronized是从悲观的角度出发:
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线
程阻塞,用完后再把资源转让给其它线程 )。因此Synchronized我们也将其称之为悲观锁。jdk中的ReentrantLock也是一种悲观锁。
CAS是从乐观的角度出发:
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。CAS这种机制我们也可以将其称之为乐观锁。
5 并发工具类 在JDK的并发包里提供了几个非常有用的并发容器和并发工具类。供我们在多线程开发中进行使用。
5.1 ConcurrentHashMap 5.1.1 概述以及基本使用 在集合类中HashMap是比较常用的集合对象,但是HashMap是线程不安全的(多线程环境下可能会存在问题)。为了保证数据的安全性我们可以使用Hashtable,但是Hashtable的效率低下。
基于以上两个原因我们可以使用JDK1.5以后所提供的ConcurrentHashMap。
案例1
实现步骤
创建一个HashMap集合对象
创建两个线程对象,第一个线程对象向集合中添加元素(1-24),第二个线程对象向集合中添加元素(25-50);
主线程休眠1秒,以便让其他两个线程将数据填装完毕
从集合中找出键和值不相同的数据
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 public class HashMapDemo01 { public static void main (String[] args) { HashMap<String , String> hashMap = new HashMap <String , String>() ; Thread t1 = new Thread () { @Override public void run () { for (int x = 1 ; x < 25 ; x++) { hashMap.put(String.valueOf(x) , String.valueOf(x)) ; } } }; Thread t2 = new Thread () { @Override public void run () { for (int x = 25 ; x < 51 ; x++) { hashMap.put(String.valueOf(x) , String.valueOf(x)) ; } } }; t1.start(); t2.start(); System.out.println("----------------------------------------------------------" ); try { TimeUnit.SECONDS.sleep(2 ); } catch (InterruptedException e) { e.printStackTrace(); } for (int x = 1 ; x < 51 ; x++) { if ( !String.valueOf(x).equals( hashMap.get(String.valueOf(x)) ) ) { System.out.println(String.valueOf(x) + ":" + hashMap.get(String.valueOf(x))); } } } }
控制台输出结果
1 2 ---------------------------------------------------------- 5 :null
通过控制台的输出结果,我们可以看到在多线程操作HashMap的时候,可能会出现线程安全问题。
注1:需要多次运行才可以看到具体的效果; 可以使用循环将代码进行改造,以便让问题方便的暴露出来!
案例2
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 public class HashtableDemo01 { public static void main (String[] args) { Hashtable<String , String> hashtable = new Hashtable <String , String>() ; Thread t1 = new Thread () { @Override public void run () { for (int x = 1 ; x < 25 ; x++) { hashtable.put(String.valueOf(x) , String.valueOf(x)) ; } } }; Thread t2 = new Thread () { @Override public void run () { for (int x = 25 ; x < 51 ; x++) { hashtable.put(String.valueOf(x) , String.valueOf(x)) ; } } }; t1.start(); t2.start(); System.out.println("----------------------------------------------------------" ); try { TimeUnit.SECONDS.sleep(2 ); } catch (InterruptedException e) { e.printStackTrace(); } for (int x = 1 ; x < 51 ; x++) { if ( !String.valueOf(x).equals( hashtable.get(String.valueOf(x)) ) ) { System.out.println(String.valueOf(x) + ":" + hashtable.get(String.valueOf(x))); } } } }
不论该程序运行多少次,都不会产生数据问题。因此也就证明Hashtable是线程安全的。
Hashtable保证线程安全的原理
查看Hashtable的源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class Hashtable <K,V> extends Dictionary <K,V> implements Map <K,V>, Cloneable, java.io.Serializable { private transient Entry<?,?>[] table; private static class Entry <K,V> implements Map .Entry<K,V> { final int hash; final K key; V value; Entry<K,V> next; } public synchronized V put (K key, V value) {...} public synchronized V get (Object key) {...} public synchronized int size () {...} ... }
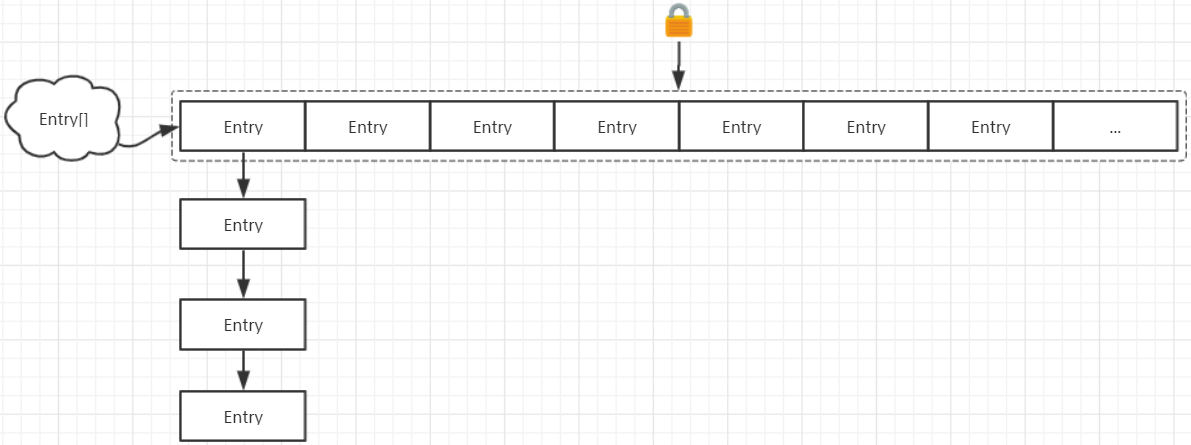
对应的结构如下图所示
Hashtable保证线程安全性的是使用方法全局锁进行实现的。在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法,其他线程也访问HashTable
的同步方法时,会进入阻塞状态。如线程1使用put进行元素添加,线程2不但不能使用put方法添加元素,也不能使用get方法来获取元素,所以竞争越激烈效率越低。
案例3
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 public class ConcurrentHashMapDemo01 { public static void main (String[] args) { ConcurrentHashMap<String , String> concurrentHashMap = new ConcurrentHashMap <String , String>() ; Thread t1 = new Thread () { @Override public void run () { for (int x = 1 ; x < 25 ; x++) { concurrentHashMap.put(String.valueOf(x) , String.valueOf(x)) ; } } }; Thread t2 = new Thread () { @Override public void run () { for (int x = 25 ; x < 51 ; x++) { concurrentHashMap.put(String.valueOf(x) , String.valueOf(x)) ; } } }; t1.start(); t2.start(); System.out.println("----------------------------------------------------------" ); try { TimeUnit.SECONDS.sleep(2 ); } catch (InterruptedException e) { e.printStackTrace(); } for (int x = 1 ; x < 51 ; x++) { if ( !String.valueOf(x).equals( concurrentHashMap.get(String.valueOf(x)) ) ) { System.out.println(String.valueOf(x) + ":" + concurrentHashMap.get(String.valueOf(x))); } } } }
不论该程序运行多少次,都不会产生数据问题。因此也就证明ConcurrentHashMap是线程安全的。
5.1.2 源码分析 由于ConcurrentHashMap在jdk1.7和jdk1.8的时候实现原理不太相同,因此需要分别来讲解一下两个不同版本的实现原理。
1) jdk1.7版本 ConcurrentHashMap中的重要成员变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class ConcurrentHashMap <K, V> extends AbstractMap <K, V> implements ConcurrentMap <K, V>, Serializable { final Segment<K,V>[] segments; static final class Segment <K,V> extends ReentrantLock implements Serializable { transient volatile int count; transient int modCount; transient int threshold; transient volatile HashEntry<K,V>[] table; final float loadFactor; } static final class HashEntry <K,V> { final int hash; final K key; volatile V value; volatile HashEntry<K,V> next; } }
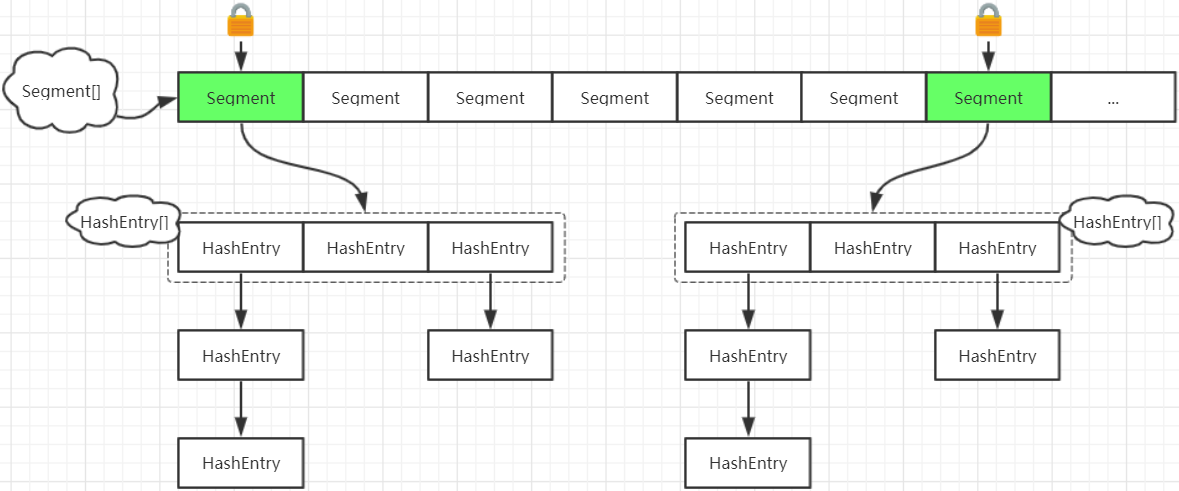
对应的结构如下图所示
简单来讲,就是ConcurrentHashMap比HashMap多了一次hash过程,第1次hash定位到Segment,第2次hash定位到HashEntry,然后链表搜索找到指定节点。在进行写操作时,只需锁住写
元素所在的Segment即可(这种锁被称为分段锁
(因为需要进行两次hash操作)。
ConcurrentHashMap的put方法源码分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 public class ConcurrentHashMap <K, V> extends AbstractMap <K, V> implements ConcurrentMap <K, V>, Serializable { public V put (K key, V value) { Segment<K,V> s; if (value == null ) throw new NullPointerException (); int hash = hash(key); int j = (hash >>> segmentShift) & segmentMask; if ((s = (Segment<K,V>)UNSAFE.getObject(segments, (j << SSHIFT) + SBASE)) == null ) s = ensureSegment(j); return s.put(key, hash, value, false ); } static final class Segment <K,V> extends ReentrantLock implements Serializable { final V put (K key, int hash, V value, boolean onlyIfAbsent) { HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value); V oldValue; try { HashEntry<K,V>[] tab = table; int index = (tab.length - 1 ) & hash; HashEntry<K,V> first = entryAt(tab, index); for (HashEntry<K,V> e = first;;) if (e != null ) { K k; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { oldValue = e.value; if (!onlyIfAbsent) { e.value = value; ++modCount; } break ; } e = e.next; } else { if (node != null ) node.setNext(first); else node = new HashEntry <K,V>(hash, key, value, first); int c = count + 1 ; if (c > threshold && tab.length < MAXIMUM_CAPACITY) rehash(node); else setEntryAt(tab, index, node); ++modCount; count = c; oldValue = null ; break ; } } } finally { unlock(); } return oldValue; } } }
注:源代码进行简单讲解即可(核心:进行了两次哈希定位以及加锁过程)
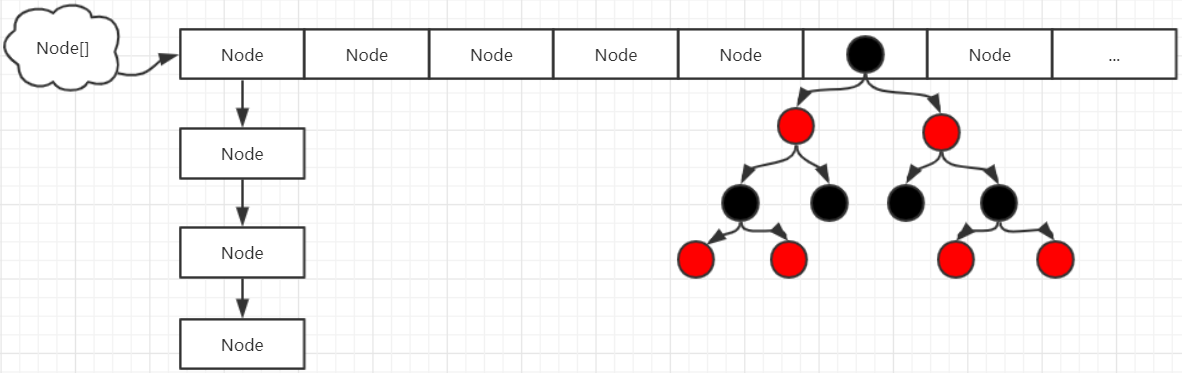
2) jdk1.8版本 在JDK1.8中为了进一步优化ConcurrentHashMap的性能,去掉了Segment分段锁的设计。在数据结构方面,则是跟HashMap一样,使用一个哈希表table数组。(数组 + 链表 + 红黑树)
而线程安全方面是结合CAS机制 + 局部锁实现的,减低锁的粒度,提高性能。同时在HashMap的基础上,对哈希表table数组和链表节点的value,next指针等使用volatile来修饰,从而
实现线程可见性。
ConcurrentHashMap中的重要成员变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class ConcurrentHashMap <K,V> extends AbstractMap <K,V> implements ConcurrentMap <K,V>, Serializable { transient volatile Node<K,V>[] table; static class Node <K,V> implements Map .Entry<K,V> { final int hash; final K key; volatile V val; volatile Node<K,V> next; } static final class TreeNode <K,V> extends Node <K,V> { TreeNode<K,V> parent; TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; boolean red; } }
对应的结构如下图
ConcurrentHashMap的put方法源码分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 public class ConcurrentHashMap <K,V> extends AbstractMap <K,V> implements ConcurrentMap <K,V>, Serializable { public V put (K key, V value) { return putVal(key, value, false ); } final V putVal (K key, V value, boolean onlyIfAbsent) { if (key == null || value == null ) throw new NullPointerException (); int hash = spread(key.hashCode()); int binCount = 0 ; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; if (tab == null || (n = tab.length) == 0 ) tab = initTable(); else if ((f = tabAt(tab, i = (n - 1 ) & hash)) == null ) { if (casTabAt(tab, i, null , new Node <K,V>(hash, key, value, null ))) break ; } else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); else { V oldVal = null ; synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0 ) { binCount = 1 ; for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break ; } Node<K,V> pred = e; if ((e = e.next) == null ) { pred.next = new Node <K,V>(hash, key, value, null ); break ; } } } else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2 ; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null ) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0 ) { if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null ) return oldVal; break ; } } } addCount(1L , binCount); return null ; } private static final sun.misc.Unsafe U; static { try { U = sun.misc.Unsafe.getUnsafe(); ... } catch (Exception e) { throw new Error (e); } } static final <K,V> Node<K,V> tabAt (Node<K,V>[] tab, int i) { return (Node<K,V>)U.getObjectVolatile(tab, ((long )i << ASHIFT) + ABASE); } static final <K,V> boolean casTabAt (Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v) { return U.compareAndSwapObject(tab, ((long )i << ASHIFT) + ABASE, c, v); } }
简单总结:
如果当前需要put的key对应的链表在哈希表table中还不存在,即还没添加过该key的hash值对应的链表,则调用casTabAt方法,基于CAS机制来实现添加该链表头结点到哈希表
table中,避免该线程在添加该链表头结的时候,其他线程也在添加的并发问题;如果CAS失败,则进行自旋,通过继续第2步的操作;
如果需要添加的链表已经存在哈希表table中,则通过tabAt方法,基于volatile机制,获取当前最新的链表头结点f,由于f指向的是ConcurrentHashMap的哈希表table的某条
链表的头结点,故虽然f是临时变量,由于是引用共享的该链表头结点,所以可以使用synchronized关键字来同步多个线程对该链表的访问。在synchronized(f)同步块里面则是与
HashMap一样遍历该链表,如果该key对应的链表节点已经存在,则更新,否则在链表的末尾新增该key对应的链表节点。
5.2 CountDownLatch CountDownLatch允许一个或多个线程等待其他线程完成操作以后,再执行当前线程;比如我们在主线程需要开启2个其他线程,当其他的线程执行完毕以后我们再去执行主线程,针对这
个需求我们就可以使用CountDownLatch来进行实现。CountDownLatch中count down是倒着数数的意思;CountDownLatch是通过一个计数器来实现的,每当一个线程完成了自己的
任务后,可以调用countDown()方法让计数器-1,当计数器到达0时,调用CountDownLatch的await()方法的线程阻塞状态解除,继续执行。
CountDownLatch的相关方法
1 2 3 public CountDownLatch (int count) public void await () throws InterruptedException public void countDown ()
案例演示:使用CountDownLatch完成上述需求(我们在主线程需要开启2个其他线程,当其他的线程执行完毕以后我们再去执行主线程)
实现思路:在main方法中创建一个CountDownLatch对象,把这个对象作为作为参数传递给其他的两个任务线程
线程任务类1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class CountDownLatchThread01 implements Runnable { private CountDownLatch countDownLatch ; public CountDownLatchThread01 (CountDownLatch countDownLatch) { this .countDownLatch = countDownLatch ; } @Override public void run () { try { Thread.sleep(10000 ); System.out.println("10秒以后执行了CountDownLatchThread01......" ); } catch (InterruptedException e) { e.printStackTrace(); } countDownLatch.countDown(); } }
线程任务类2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class CountDownLatchThread02 implements Runnable { private CountDownLatch countDownLatch ; public CountDownLatchThread02 (CountDownLatch countDownLatch) { this .countDownLatch = countDownLatch ; } @Override public void run () { try { Thread.sleep(3000 ); System.out.println("3秒以后执行了CountDownLatchThread02......" ); } catch (InterruptedException e) { e.printStackTrace(); } countDownLatch.countDown(); } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class CountDownLatchDemo01 { public static void main (String[] args) { CountDownLatch countDownLatch = new CountDownLatch (2 ) ; CountDownLatchThread01 countDownLatchThread01 = new CountDownLatchThread01 (countDownLatch) ; CountDownLatchThread02 countDownLatchThread02 = new CountDownLatchThread02 (countDownLatch) ; Thread t1 = new Thread (countDownLatchThread01); Thread t2 = new Thread (countDownLatchThread02); t1.start(); t2.start(); try { countDownLatch.await(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("主线程执行了.... 程序结束了......" ); } }
控制台输出结果
1 2 3 3 秒以后执行了CountDownLatchThread02......10 秒以后执行了CountDownLatchThread01......主线程执行了.... 程序结束了......
CountDownLatchThread02线程先执行完毕,此时计数器-1;CountDownLatchThread01线程执行完毕,此时计数器-1;当计数器的值为0的时候,主线程阻塞状态接触,主线程向下执行。
5.3 CyclicBarrier 5.3.1 概述以及基本使用 CyclicBarrier的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障
才会开门,所有被屏障拦截的线程才会继续运行。
例如:公司召集5名员工开会,等5名员工都到了,会议开始。我们创建5个员工线程,1个开会线程,几乎同时启动,使用CyclicBarrier保证5名员工线程全部执行后,再执行开会线程。
CyclicBarrier的相关方法
1 2 public CyclicBarrier (int parties, Runnable barrierAction) public int await ()
案例演示:模拟员工开会
实现步骤:
创建一个员工线程类(EmployeeThread),该线程类中需要定义一个CyclicBarrier类型的形式参数
创建一个开会线程类(MettingThread)
测试类
创建CyclicBarrier对象
创建5个EmployeeThread线程对象,把第一步创建的CyclicBarrier对象作为构造方法参数传递过来
启动5个员工线程
员工线程类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class EmployeeThread extends Thread { private CyclicBarrier cyclicBarrier ; public EmployeeThread (CyclicBarrier cyclicBarrier) { this .cyclicBarrier = cyclicBarrier ; } @Override public void run () { try { Thread.sleep((int ) (Math.random() * 1000 )); System.out.println(Thread.currentThread().getName() + " 到了! " ); cyclicBarrier.await(); } catch (Exception e) { e.printStackTrace(); } } }
开会线程类
1 2 3 4 5 6 7 8 public class MettingThread extends Thread { @Override public void run () { System.out.println("好了,人都到了,开始开会......" ); } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class CyclicBarrierDemo01 { public static void main (String[] args) { CyclicBarrier cyclicBarrier = new CyclicBarrier (5 , new MettingThread ()) ; EmployeeThread thread1 = new EmployeeThread (cyclicBarrier) ; EmployeeThread thread2 = new EmployeeThread (cyclicBarrier) ; EmployeeThread thread3 = new EmployeeThread (cyclicBarrier) ; EmployeeThread thread4 = new EmployeeThread (cyclicBarrier) ; EmployeeThread thread5 = new EmployeeThread (cyclicBarrier) ; thread1.start(); thread2.start(); thread3.start(); thread4.start(); thread5.start(); } }
5.3.2 使用场景 使用场景:CyclicBarrier可以用于多线程计算数据,最后合并计算结果的场景。
比如:现在存在两个文件,这个两个文件中存储的是某一个员工两年的工资信息(一年一个文件),现需要对这两个文件中的数据进行汇总;使用两个线程读取2个文件中的数据,当两个文
件中的数据都读取完毕以后,进行数据的汇总操作。
分析:要想在两个线程读取数据完毕以后进行数据的汇总,那么我们就需要定义一个任务类(该类需要实现Runnable接口);两个线程读取完数据以后再进行数据的汇总,那么我们可以将
两个线程读取到的数据先存储到一个集合中,而多线程环境下最常见的线程集合类就是ConcurrentHashMap,而这个集合需要被两个线程都可以进行使用,那么我们可以将这个集
合作为我们任务类的成员变量,然后我们在这个任务类中去定义一个CyclicBarrier对象,然后在定义一个方法(count),当调用这个count方法的时候需要去开启两个线程对象,
使用这两个线程对象读取数据,把读取到的数据存储到ConcurrentHashMap对象,当一个线程读取数据完毕以后,调用CyclicBarrier的awit方法(告诉CyclicBarrier我已经
到达了屏障),然后在任务类的run方法对ConcurrentHashMap的数据进行汇总操作;
实现步骤:
定义一个任务类CyclicBarrierThreadUse(实现了Runnable接口)
定义成员变量:CyclicBarrier ,ConcurrentHashMap
1 2 private CyclicBarrier cyclicBarrier = new CyclicBarrier (2 , this ) ;private ConcurrentHashMap<Integer , String> concurrentHashMap = new ConcurrentHashMap <Integer , String>() ;
定义一个方法count方法,在count方法中开启两个线程对象(可以使用匿名内部类的方式实现)
在run方法中对ConcurrentHashMap中的数据进行汇总
编写测试类CyclicBarrierThreadUseDemo
创建CyclicBarrierThreadUse对象,调用count方法
任务类代代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 public class CyclicBarrierThreadUse implements Runnable { private CyclicBarrier cyclicBarrier = new CyclicBarrier (2 , this ) ; private ConcurrentHashMap<Integer , String> concurrentHashMap = new ConcurrentHashMap <Integer , String>() ; public void count () { new Thread (new Runnable () { @Override public void run () { BufferedReader bufferedReader = null ; try { bufferedReader = new BufferedReader (new FileReader ("D:\\salary\\2017-salary.txt" )) ; String line = null ; while ((line = bufferedReader.readLine()) != null ) { concurrentHashMap.put(Integer.parseInt(line) , "" ) ; } } catch (Exception e) { e.printStackTrace(); } finally { if (bufferedReader != null ) { try { bufferedReader.close(); } catch (IOException e) { e.printStackTrace(); } } } try { TimeUnit.SECONDS.sleep(5 ) ; System.out.println(Thread.currentThread().getName() + "---------------------线程读取数据完毕...." ); cyclicBarrier.await() ; } catch (Exception e) { e.printStackTrace(); } } }).start(); new Thread (new Runnable () { @Override public void run () { BufferedReader bufferedReader = null ; try { bufferedReader = new BufferedReader (new FileReader ("D:\\salary\\2019-salary.txt" )) ; String line = null ; while ((line = bufferedReader.readLine()) != null ) { concurrentHashMap.put(Integer.parseInt(line) , "" ) ; } } catch (Exception e) { e.printStackTrace(); } finally { if (bufferedReader != null ) { try { bufferedReader.close(); } catch (IOException e) { e.printStackTrace(); } } } try { TimeUnit.SECONDS.sleep(10 ) ; System.out.println(Thread.currentThread().getName() + "---------------------线程读取数据完毕...." ); cyclicBarrier.await() ; } catch (Exception e) { e.printStackTrace(); } } }).start(); } @Override public void run () { Enumeration<Integer> enumeration = concurrentHashMap.keys(); int result = 0 ; while (enumeration.hasMoreElements()) { Integer integer = enumeration.nextElement(); result += integer ; } System.out.println(result); } }
测试类代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 public class CyclicBarrierThreadUseDemo01 { public static void main (String[] args) { CyclicBarrierThreadUse cyclicBarrierThreadUse = new CyclicBarrierThreadUse (); cyclicBarrierThreadUse.count(); } }
5.4 Semaphore Semaphore字面意思是信号量的意思,它的作用是控制访问特定资源的线程数目。
举例:现在有一个十字路口,有多辆汽车需要进经过这个十字路口,但是我们规定同时只能有两辆汽车经过。其他汽车处于等待状态,只要某一个汽车经过了这个十字路口,其他的汽车才可以经
过,但是同时只能有两个汽车经过。如何限定经过这个十字路口车辆数目呢? 我们就可以使用Semaphore。
Semaphore的常用方法
1 2 3 public Semaphore (int permits ) permits 表示许可线程的数量public void acquire () throws InterruptedException 表示获取许可public void release () 表示释放许可
案例演示:模拟汽车通过十字路口
实现步骤:
创建一个汽车的线程任务类(CarThreadRunnable),在该类中定义一个Semaphore类型的成员变量
创建测试类
创建线程任务类对象
创建5个线程对象,并启动。(5个线程对象,相当于5辆汽车)
CarThreadRunnable类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class CarThreadRunnable implements Runnable { private Semaphore semaphore = new Semaphore (2 ) ; @Override public void run () { try { semaphore.acquire(); System.out.println(Thread.currentThread().getName() + "----->>正在经过十字路口" ); Random random = new Random (); int nextInt = random.nextInt(7 ); TimeUnit.SECONDS.sleep(nextInt); System.out.println(Thread.currentThread().getName() + "----->>驶出十字路口" ); semaphore.release(); } catch (InterruptedException e) { e.printStackTrace(); } } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class SemaphoreDemo01 { public static void main (String[] args) { CarThreadRunnable carThreadRunnable = new CarThreadRunnable () ; for (int x = 0 ; x < 5 ; x++) { new Thread (carThreadRunnable).start(); } } }
控制台输出结果
1 2 3 4 5 6 7 8 9 10 Thread-0 ----->>正在经过十字路口 Thread-1 ----->>正在经过十字路口 Thread-1 ----->>驶出十字路口 Thread-2 ----->>正在经过十字路口 Thread-0 ----->>驶出十字路口 Thread-3 ----->>正在经过十字路口 Thread-2 ----->>驶出十字路口 Thread-4 ----->>正在经过十字路口 Thread-4 ----->>驶出十字路口 Thread-3 ----->>驶出十字路口
通过控制台输出,我们可以看到当某一个汽车”驶出”十字路口以后,就会有一个汽车立马驶入。
5.5 Exchanger 5.5.1 概述以及基本使用 Exchanger(交换者)是一个用于线程间协作的工具类。Exchanger用于进行线程间的数据交换。
举例:比如男女双方结婚的时候,需要进行交换结婚戒指。
Exchanger常用方法
1 2 public Exchanger () public V exchange (V x)
这两个线程通过exchange方法交换数据,如果第一个线程先执行exchange()方法,它会一直等待第二个线程也执行exchange方法,当两个线程都到达同步点时,这两个线程就可以交换数据,
将本线程生产出来的数据传递给对方。
案例演示:模拟交互结婚戒指
实现步骤:
创建一个男方的线程类(ManThread),定义一个Exchanger类型的成员变量
创建一个女方的线程类(WomanThread),定义一个Exchanger类型的成员变量
测试类
创建一个Exchanger对象
创建一个ManThread对象,把第一步所创建的Exchanger作为构造方法参数传递过来
创建一个WomanThread对象,把第一步所创建的Exchanger作为构造方法参数传递过来
启动两个线程
ManThread类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class ManThread extends Thread { private Exchanger<String> exchanger ; private String name ; public ManThread (Exchange<String> exchanger , String name) { super (name); this .name = name ; this .exchanger = exchanger ; } @Override public void run () { try { String result = exchanger.exchange("钻戒" ); System.out.println(name + "---->>把钻戒给媳妇" ); System.out.println(name + "---->>得到媳妇给的" + result); } catch (InterruptedException e) { e.printStackTrace(); } } }
WomanThread类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class WomanThread extends Thread { private Exchanger<String> exchanger ; private String name ; public WomanThread (Exchanger<String> exchanger , String name) { super (name) ; this .name = name ; this .exchanger = exchanger ; } @Override public void run () { try { String result = exchanger.exchange("铝戒" ); System.out.println(name + "---->>把铝戒给老公" ); System.out.println(name + "---->>得到老公给的" + result); } catch (InterruptedException e) { e.printStackTrace(); } } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class ExchangerDemo01 { public static void main (String[] args) { Exchanger<String> exchanger = new Exchanger <String>() ; ManThread manThread = new ManThread (exchanger , "杨过" ) ; WomanThread womanThread = new WomanThread (exchanger , "小龙女" ) ; manThread.start(); womanThread.start(); } }
5.5.2 使用场景 使用场景:可以做数据校对工作
比如: 现在存在一个文件,该文件中存储的是某一个员工一年的工资信息,现需要将这个员工的工资信息录入到系统中,采用AB岗两人进行录入,录入到两个文件中,系统需要加载这两
个文件,并对两个文件数据进行校对,看看是否录入一致,
实现步骤:
创建一个测试类(ExchangerUseDemo)
通过匿名内部类的方法创建两个线程对象
两个线程分别读取文件中的数据,然后将数据存储到各自的集合中
当每一个线程读取完数据以后,就将数据交换给对方
然后每个线程使用对方传递过来的数据与自己所录入的数据进行比对
ExchangerUseDemo类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 public class ExchangerUseDemo { public static void main (String[] args) { Exchanger<ArrayList<String>> exchanger = new Exchanger <ArrayList<String>>() ; new Thread (new Runnable () { @Override public void run () { try { ArrayList<String> arrayList = new ArrayList <String>() ; BufferedReader bufferedReader = new BufferedReader (new FileReader ("D:\\salary\\2017-salary.txt" )) ; String line = null ; while ((line = bufferedReader.readLine()) != null ) { arrayList.add(line) ; } arrayList.remove(0 ) ; ArrayList<String> exchange = exchanger.exchange(arrayList); if (arrayList.size() == exchange.size()) { for (int x = 0 ; x < arrayList.size() ; x++) { String benfangElement = arrayList.get(x); String duifangElement = exchange.get(x); if (!benfangElement.equals(duifangElement)) { System.out.println("数据存在问题....." ); } } }else { System.out.println("数据存在问题....." ); } } catch (Exception e) { e.printStackTrace(); } } }).start(); new Thread (new Runnable () { @Override public void run () { try { ArrayList<String> arrayList = new ArrayList <String>() ; BufferedReader bufferedReader = new BufferedReader (new FileReader ("D:\\salary\\2017-salary.txt" )) ; String line = null ; while ((line = bufferedReader.readLine()) != null ) { arrayList.add(line) ; } ArrayList<String> exchange = exchanger.exchange(arrayList); if (arrayList.size() == exchange.size()) { for (int x = 0 ; x < arrayList.size() ; x++) { String benfangElement = arrayList.get(x); String duifangElement = exchange.get(x); if (!benfangElement.equals(duifangElement)) { System.out.println("数据存在问题....." ); } } }else { System.out.println("数据存在问题....." ); } } catch (Exception e) { e.printStackTrace(); } } }).start(); } }




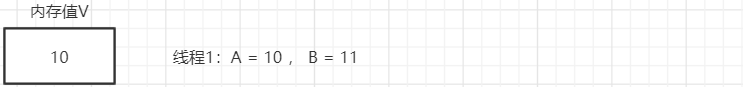


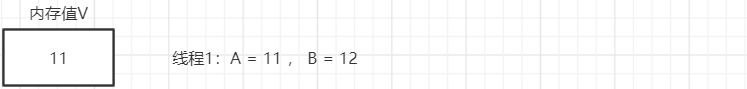


 微信
微信 支付宝
支付宝